Bot Battles Player Analysis - Part 1: Data Cleaning
Goal: Clean the Bot Battles data in preparation for analysis.
PostgreSQLData Cleaning
Background
This article covers part 1 and is meant to detail my process as I progress through cleaning the data. I'll discuss the obstacles that I encounter, how I overcome them, and my overall logic in general.
An introduction to the game and the data can be found here. The full project containing the code and both the original and cleaned versions of the data can be found on my GitHub.
Section 1: Loading the Dataset
SQL QueriesThe dataset comes in two csv files, users.csv and event_performance.csv
users.csv
| Field | Description |
|---|---|
| userid | A string that uniquely identifies a player |
| subscriber | A binary variable identifying whether the userid is a paid subscriber or not |
| country | A variable that identifies which country a userid is from, either 'CA' (Canada), 'US' (United States), or 'MX' (Mexico) |
event_performance.csv
| Field | Description |
|---|---|
| userid | A string that uniquely identifies a player |
| event_date | The date corresponding to when the userid participated in a gaming event |
| hour | The hour of the day in which the userid participated in the gaming event |
| points | The number of points scored by the userid during a single hour of gameplay |
Section 2: Checking for Null and Duplicate Values
SQL QueriesNo rows are returned by any of the queries. There are no null or duplicate values in any of the columns in either of the tables.
Section 3: Inspecting the users_staging Table
SQL Queriesuserid
All userids are 36 characters long and are a mixture of alphanumeric characters.
subscriber
Subscriber is a binary variable. A value of 0 means the user isn't a subscriber, while a value of 1 means they are a subscriber. All values in the dataset are either 0 or 1, as they're supposed to be.
country
Country is a two character string representing which country a user is from. All players are from 'CA' (Canada), 'US' (United States), or 'MX' (Mexico).
Section 4: Inspecting the events_performance_staging Table
SQL Queriesuserid
All userids in the users_staging table had 36 characters. However, two userids in the events_performance_staging table have 37 characters.
It appears one userid had a whitespace character at the end (denoted by "\s") and the other had a double quotation mark. Later, I'll use REGEX to trim both of those characters when importing to the new tables.

event_date
The event_date field has the most obstacles to overcome. It contains several different forms of dates that aren't valid, as well as inconsistent date formats.- One of the dates is 19/24/2019 and there's no way to identify whether this date is meant to be 1/24/2019, 9/24/2019, or perhaps something else entirely. The safest option is to drop it. Dropping one entry in a dataset this size won't make much of a difference.
- Some event_dates use a 2-digit year format (MM/DD/YY) while other event_dates use a different 4-digit year format (YYYY/MM/DD). I'll convert any dates from the MM/DD/YY format to the more standard YYYY/MM/DD format.
-
Lastly, there are two dates remaining that are invalid and need to be dropped:
- One date from the future, 2039-08-02.
- One date from too far in the past to be valid, 1999-03-22.
hour
Hour represents an hour of the day. All values are in military time, ranging from 16:00 to 20:00 or 4:00 to 8:00 p.m. No cleaning is needed.
points
Using REGEX, I look for any point scores with non-numeric characters. One point score has quotation marks and the other has question marks.

Section 5: Moving Cleaned Data to New Tables
SQL Queries
Once loaded, this is what the database ERD will look like:
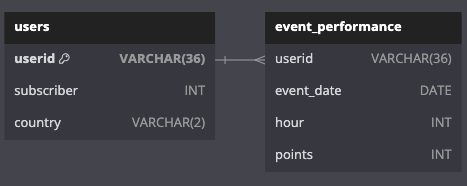
users
No cleaning was needed for the users_staging data. I simply write a query that creates a new table called users with more explicit data types and introduces constraints to ensure correct values are entered into all rows.
Here is the schema for a newly defined users table:-
userid
- Data type: VARCHAR(36)
- Constraints: PRIMARY KEY
-
subscriber
- Data type: int
- Constraints: only non-null values of 0 or 1 are allowed
-
country
- Data type: VARCHAR(2)
- Constraints: only non-null values of 'CA', 'US', or 'MX' are allowed
event_performance
The event_performance_staging table needed a little bit of cleaning. I wrote a query to create a new table called event_performance which has more explicit data types and introduces constraints. I also used REGEX to remove typos from the userid and points fields and a WHERE clause to filter out observations corresponding to invalid dates.
Here is the schema for the newly defined events_performance table:-
userid
- Data type: VARCHAR(36)
- Constraints: can't be null
- Note: I use REGEX to remove the whitespace character and the quotation marks from the userids that were 37 characters long
-
event_date
- Data type: date
- Constraints: Must be a non-null date from after the company was formed (2013-01-01) and before the current date.
- Note: I filter the dates that were identified to be invalid from earlier.
-
hour
- Data type: int
- Constraints: must be a non-null integer from 0 to 23 inclusive
-
points
- Data type: int
- Constraints: can't be null
Section 6: Next Steps
Now that the data has been cleaned and moved to new tables in the database, I begin exploring it in part 2.